Experimental Results
Quantitative Evaluation
We evaluate on the public Seed-TTS-eval benchmark and our newly constructed ZERO500 multilingual benchmark.
T1
Performance on Seed-TTS-eval Benchmark
| Model | Params | WER ↓ | SIM ↑ |
|---|---|---|---|
| MegaTTS3 | 0.5B | 2.79 | 0.77 |
| Seed-TTSDiT | — | 1.73 | 0.79 |
| DiTAR | 0.6B | 1.69 | 0.74 |
| MiniMax-Speech | — | 1.65 | 0.69 |
| F5-TTS | 0.3B | 2.00 | 0.67 |
| CosyVoice3 | 1.5B | 2.22 | 0.72 |
| Spark-TTS | 0.5B | 3.14 | 0.57 |
| OpenAudio S1-Mini | 0.5B | 1.94 | 0.55 |
| IndexTTS2 | 1.5B | 2.23 | 0.71 |
| VibeVoice | 1.5B | 3.04 | 0.69 |
| VoxCPM-Emilia | 0.5B | 2.34 | 0.68 |
| VoxCPM | 0.5B | 1.85 | 0.73 |
| Baseline | 0.06B | 1.44 | 0.60 |
| ContrastiveFM | 0.06B | 1.41 | 0.60 |
| RobustSpeechFlow | 0.06B | 1.38 | 0.60 |
T2
Results on ZERO500 at 500k Steps (%)
| Model | NFE | EN CER ↓ | EN WER ↓ | KO CER ↓ | KO WER ↓ |
|---|---|---|---|---|---|
| Baseline | 12 | 0.55 | 1.25 | 0.93 | 8.46 |
| Baseline | 24 | 0.48 | 1.18 | 0.81 | 8.40 |
| ContrastiveFM | 12 | 0.41 | 1.10 | 0.77 | 7.92 |
| ContrastiveFM | 24 | 0.39 | 1.06 | 0.65 | 7.72 |
| RobustSpeechFlow | 12 | 0.43 | 1.14 | 0.57 | 7.59 |
| RobustSpeechFlow | 24 | 0.35 | 1.03 | 0.57 | 7.45 |
F1
CER (%) over Training Steps on ZERO500
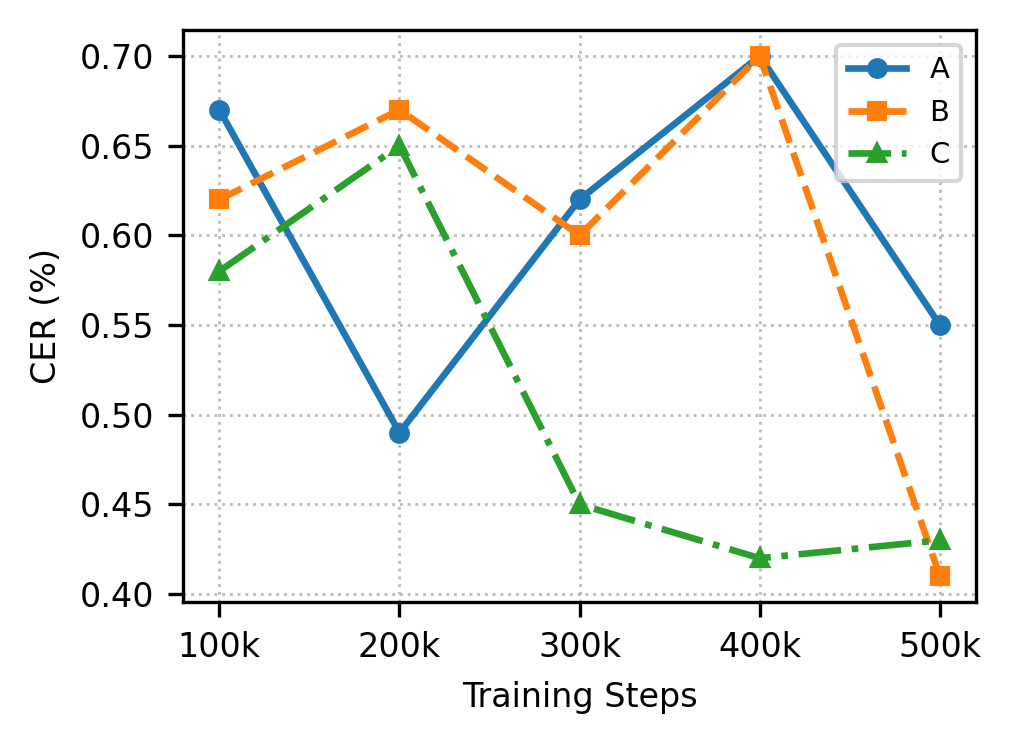
(a) ZERO500-en CER (%), NFE=12
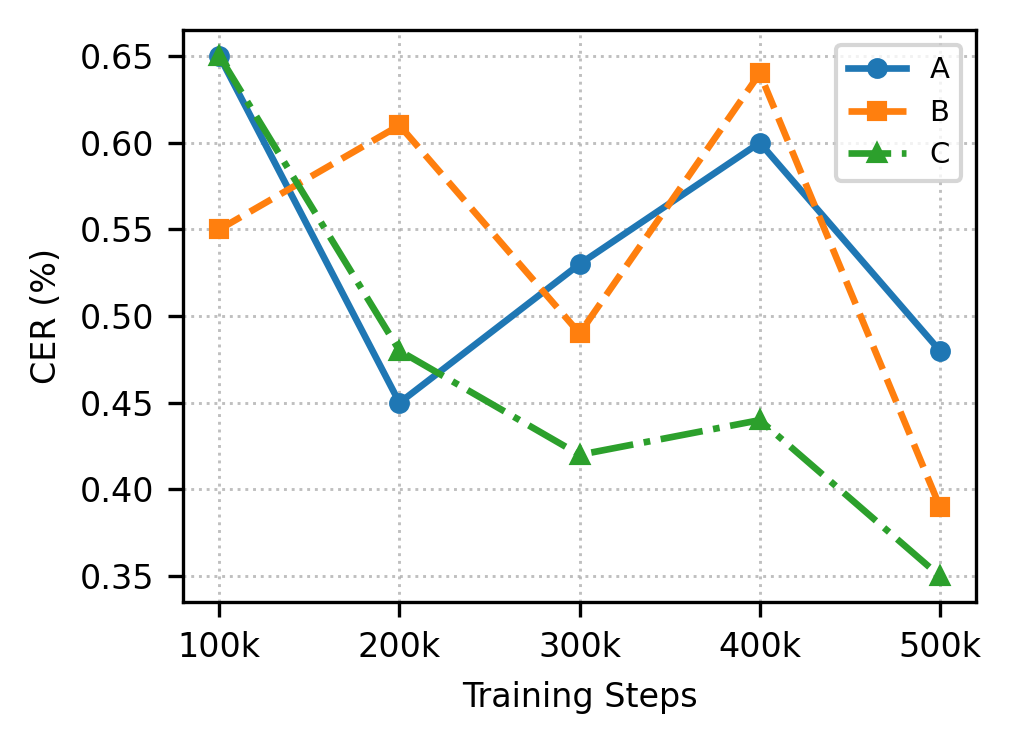
(b) ZERO500-en CER (%), NFE=24
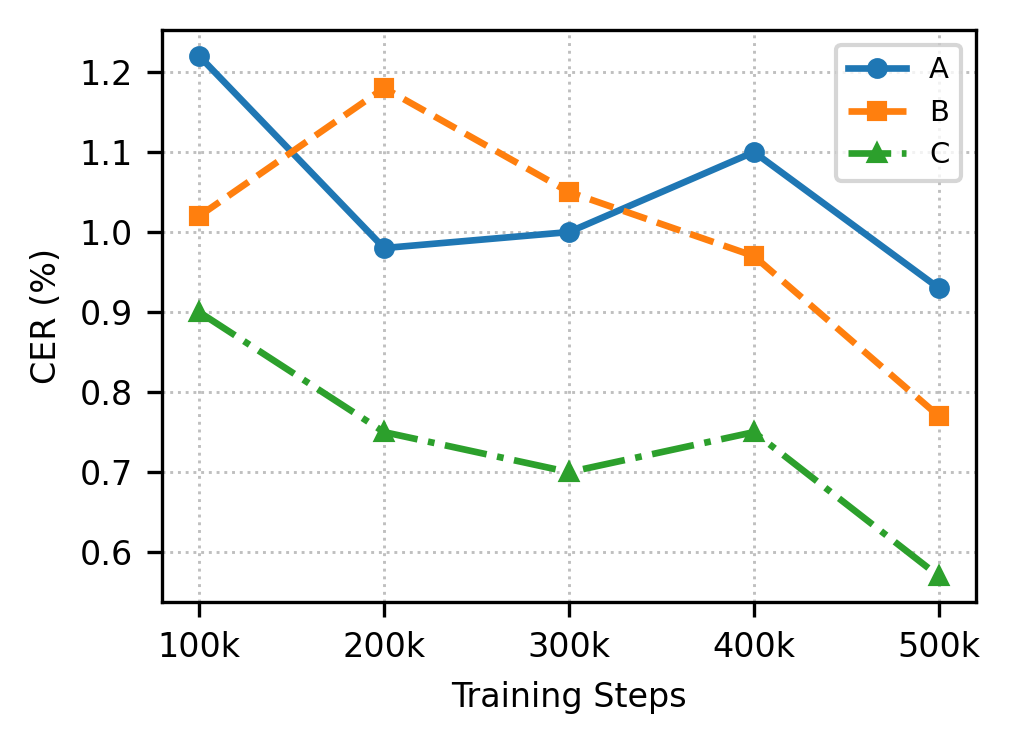
(c) ZERO500-ko CER (%), NFE=12
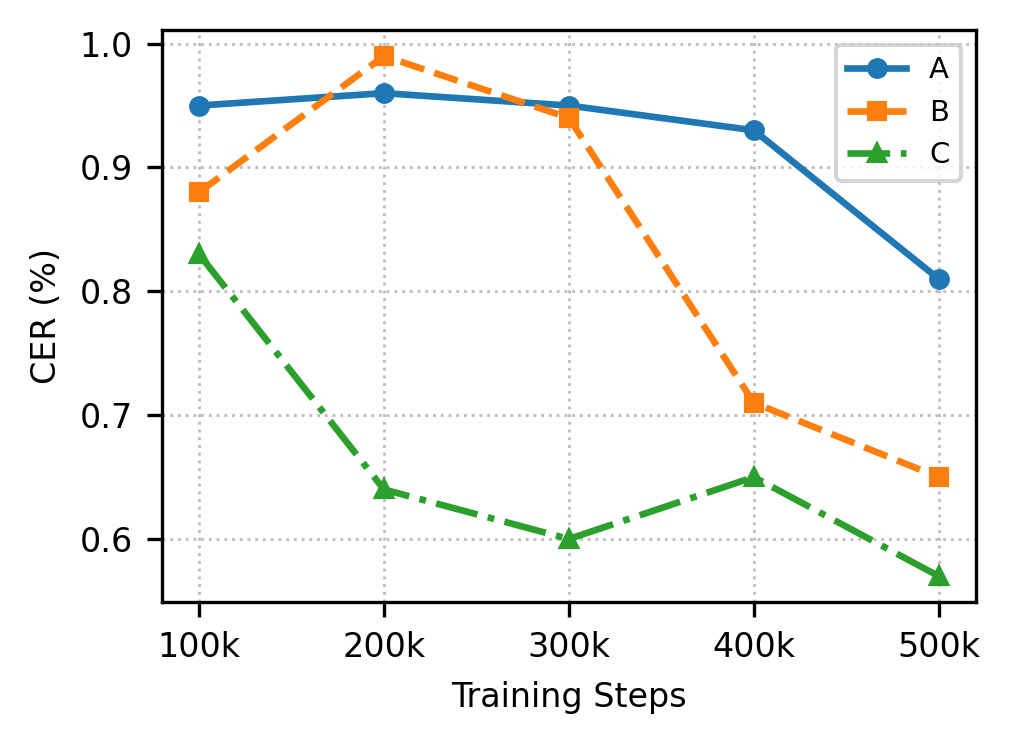
(d) ZERO500-ko CER (%), NFE=24
CER (%) over training steps on ZERO500. RobustSpeechFlow shows consistent improvement, especially on Korean and at NFE=24 where it reaches the lowest final CER. Legend: A = Baseline, B = ContrastiveFM, C = RobustSpeechFlow.